Data Engineering on Microsoft Azure
Last Update 2 months ago
Total Questions : 355
Data Engineering on Microsoft Azure is stable now with all latest exam questions are added 2 months ago. Incorporating DP-203 practice exam questions into your study plan is more than just a preparation strategy.
DP-203 exam questions often include scenarios and problem-solving exercises that mirror real-world challenges. Working through DP-203 dumps allows you to practice pacing yourself, ensuring that you can complete all Data Engineering on Microsoft Azure practice test within the allotted time frame.
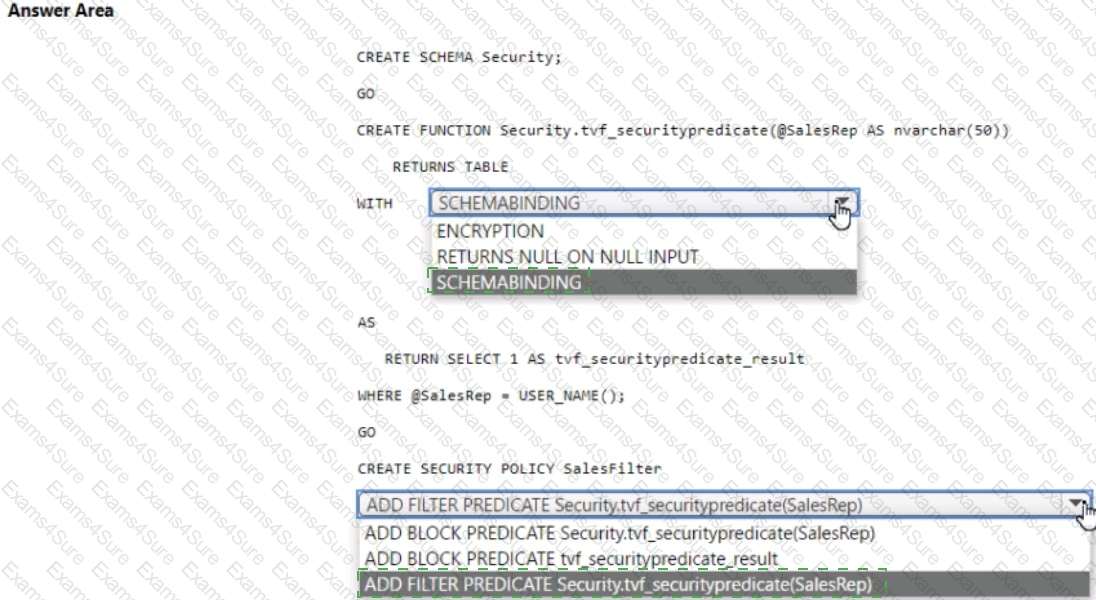
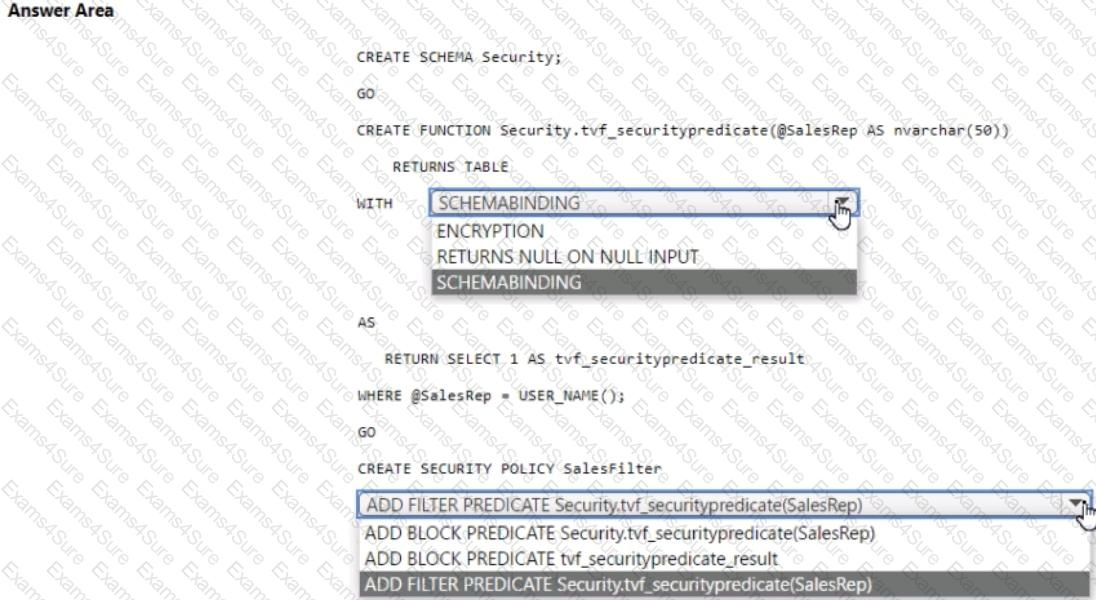
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Sales.Orders. Sales.Orders contains a column named SalesRep.
You plan to implement row-level security (RLS) for Sales.Orders.
You need to create the security policy that will be used to implement RLS. The solution must ensure that sales representatives only see rows for which the value of the SalesRep column matches their username.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
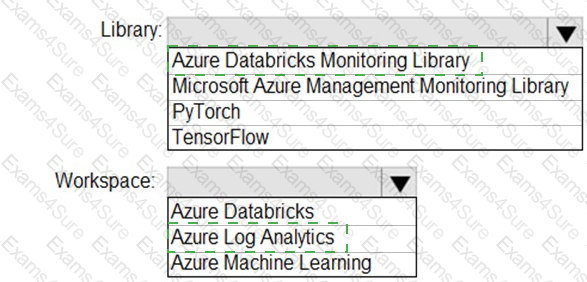
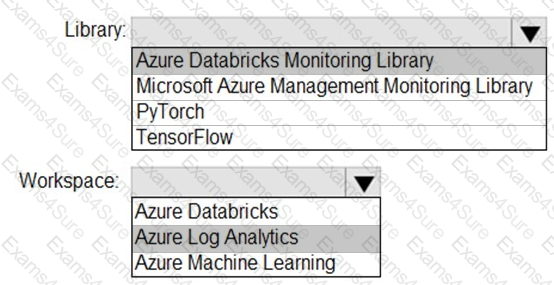
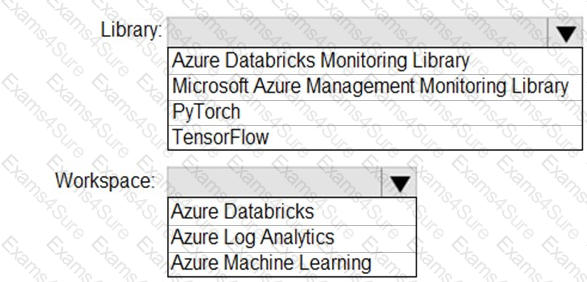
You need to collect application metrics, streaming query events, and application log messages for an Azure Databrick cluster.
Which type of library and workspace should you implement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
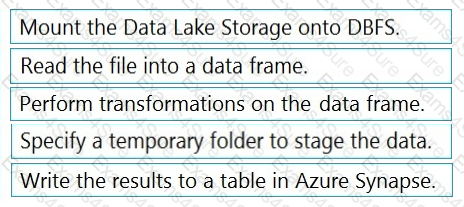
You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName.
You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values.
You create the following components:
A destination table in Azure Synapse
An Azure Blob storage container
A service principal
In which order should you perform the actions? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

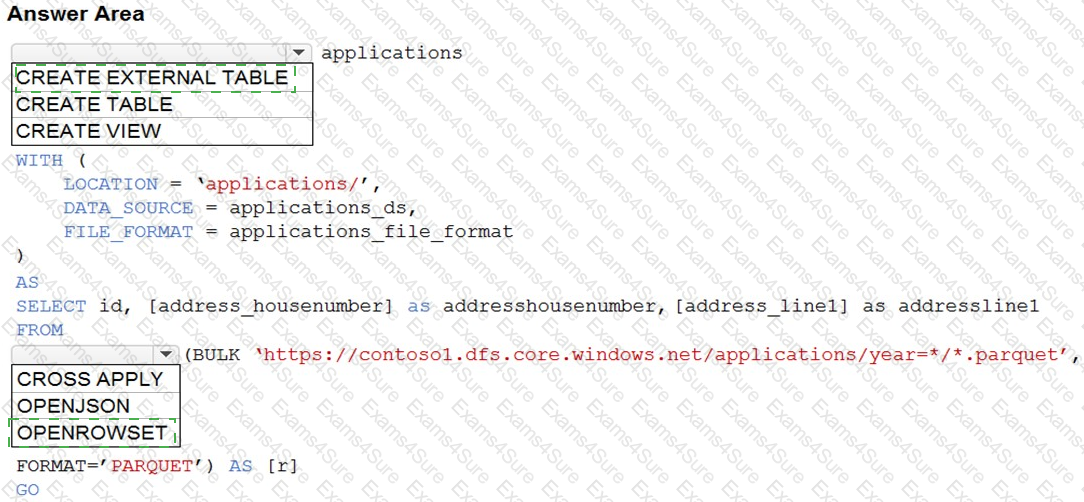
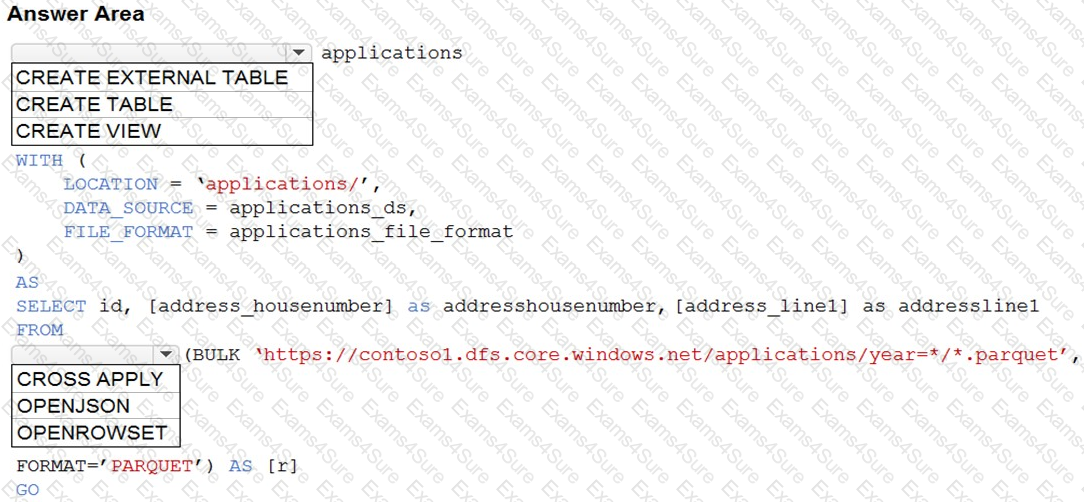
You are building a database in an Azure Synapse Analytics serverless SQL pool.
You have data stored in Parquet files in an Azure Data Lake Storage Gen2 container.
Records are structured as shown in the following sample.
{
"id": 123,
"address_housenumber": "19c",
"address_line": "Memory Lane",
"applicant1_name": "Jane",
"applicant2_name": "Dev"
}
The records contain two applicants at most.
You need to build a table that includes only the address fields.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1.
You need to determine the size of the transaction log file for each distribution of DW1.
What should you do?
You have an Azure subscription linked to an Azure Active Directory (Azure AD) tenant that contains a service principal named ServicePrincipal1. The subscription contains an Azure Data Lake Storage account named adls1. Adls1 contains a folder named Folder2 that has a URI of https://adls1.dfs.core.windows.net/container1/Folder1/Folder2/.
ServicePrincipal1 has the access control list (ACL) permissions shown in the following table.

You need to ensure that ServicePrincipal1 can perform the following actions:
Traverse child items that are created in Folder2.
Read files that are created in Folder2.
The solution must use the principle of least privilege.
Which two permissions should you grant to ServicePrincipal1 for Folder2? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Vou have an Azure Data factory pipeline that has the logic flow shown in the following exhibit.
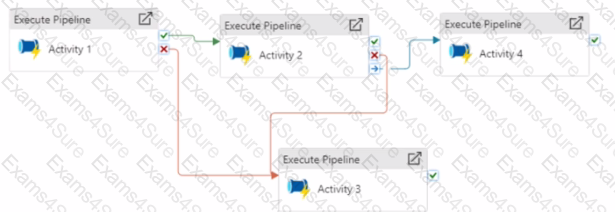
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each coned selection is worth one point.

You have a Microsoft Entra tenant.
The tenant contains an Azure Data Lake Storage Gen2 account named storage! that has two containers named fs1 and fs2. You have a Microsoft Entra group named Oepartment
A.
You need to meet the following requirements:• OepartmentA must be able to read, write, and list all the files in fs1.
• OepartmentA must be prevented from accessing any files in fs2
• The solution must use the principle of least privilege.
Which role should you assign to DepartmentA?
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is accessible only through an Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active Directory group named Sales. POSIX controls are used to assign the Sales group access to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each area selection is worth one point.
You have an Azure subscription that contains an Azure Synapse Analytics workspace and a user named Used.
You need to ensure that User1 can review the Azure Synapse Analytics database templates from the gallery. The solution must follow the principle of least privilege.
Which role should you assign to User1?


TESTED 26 Mar 2025
Hi this is Romona Kearns from Holland and I would like to tell you that I passed my exam with the use of exams4sure dumps. I got same questions in my exam that I prepared from your test engine software. I will recommend your site to all my friends for sure.
Our all material is important and it will be handy for you. If you have short time for exam so, we are sure with the use of it you will pass it easily with good marks. If you will not pass so, you could feel free to claim your refund. We will give 100% money back guarantee if our customers will not satisfy with our products.